
久しぶりの投稿だな今まで何してた?という顔をしている柴犬です。
RUSTのトレイト、ジェネリクスがなかなか理解できません。型を主体にした構成になっているのかなと思い始め、また読み直してみます。
理解できたらまたこのことについて投稿します。
概要
excelファイルを pandas で読み書きをしてみました。
次のPandas 公式ページの中の「 Input/output 」を読めば分かりますが
https://pandas.pydata.org/docs/reference/io.html流れがあると理解しやすいのでまとめてみました。
Excel 扱う準備
openpyxl と xlrd のインストール
この二つは必要ですので、コマンドプロンプトから打ち込んでインストールします。
$ pip install openpyxl
$ pip install xlrdExcel ファイルの読み込み
Excel ファイルを次のコードで pandas DataFrame に読み込みます
import pandas as pd
meibo = pd.read_excel("名簿.xlsx", engine = "openpyxl", sheet_name = None)
pandas.read_excel のソース
次の公式ページに引数の説明があります。
https://github.com/pandas-dev/pandas/blob/v1.5.3/pandas/io/excel/_base.py#L440-L520
def read_excel(
io,
sheet_name: str | int | list[IntStrT] | None = 0,
header: int | Sequence[int] | None = 0,
names: list[str] | None = None,
index_col: int | Sequence[int] | None = None,
usecols: int
| str
| Sequence[int]
| Sequence[str]
| Callable[[str], bool]
| None = None,
squeeze: bool | None = None,
dtype: DtypeArg | None = None,
engine: Literal["xlrd", "openpyxl", "odf", "pyxlsb"] | None = None,
converters: dict[str, Callable] | dict[int, Callable] | None = None,
true_values: Iterable[Hashable] | None = None,
false_values: Iterable[Hashable] | None = None,
skiprows: Sequence[int] | int | Callable[[int], object] | None = None,
nrows: int | None = None,
na_values=None,
keep_default_na: bool = True,
na_filter: bool = True,
verbose: bool = False,
parse_dates: list | dict | bool = False,
date_parser: Callable | None = None,
thousands: str | None = None,
decimal: str = ".",
comment: str | None = None,
skipfooter: int = 0,
convert_float: bool | None = None,
mangle_dupe_cols: bool = True,
storage_options: StorageOptions = None,
) -> DataFrame よく使う引数
io
iostr, bytes、ExcelFile、xlrd.Book、path object、またはfile-like object
任意の有効な文字列パスを使うことができます。sheet_name
str、int、list、または None、デフォルト 0
シート名には文字列を使用します。
整数の指定は、インデックスが 0 からのシート位置で指定します。デフォルト 0
文字列と整数のリストは、複数のシートをリクエストするために使用されます。
すべてのワークシートを取得するには、None を指定します。
例:
・なにも指定しなければデフォルト 0 で指定かあったものとして 1 番目のシートをDataFrameとして
・1 としたら 2 番目のシートを DataFrameとして
・"Sheet1"としたら 「Sheet1」という名前のシートを DataFrameとして
・list[0, 1, "Sheet5"]とすれば 1 番目、2 番目、および「Sheet5」という名前のシートをDataFrameの Dictionary として
・None とすればすべてのワークシートをDataFrameとして読み込みます。header
int、list of int、デフォルト 0
解析された DataFrame の列ラベルに使用する行 (デフォルト 0 )。
整数のリストが渡された場合、それらの行の位置は MultiIndex に結合されます。
ヘッダーがない場合は None を使用します。ファイル例
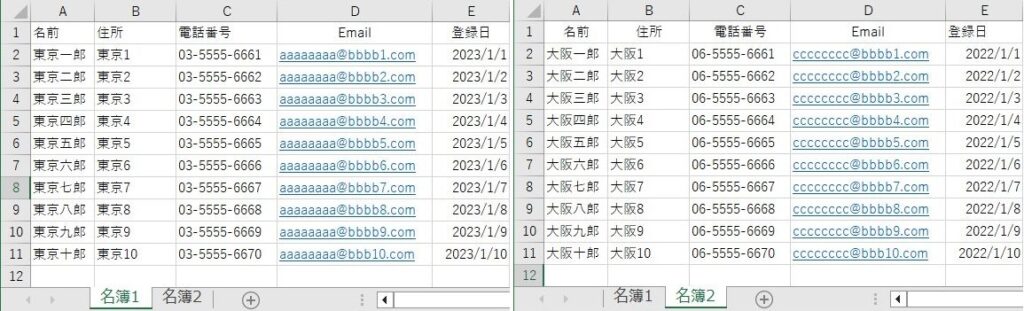
EXCELブック「名簿.xlsx」にシート「名簿1」「名簿2」が次のようになっているファイルを読み込んでみます。
読み込みを実践
最初のコードを jupyter lab から実行してみます。
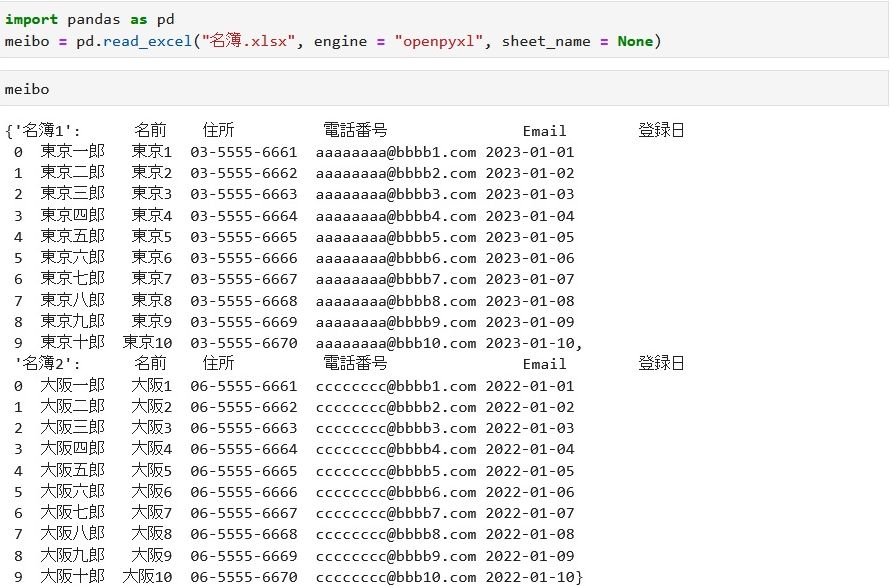
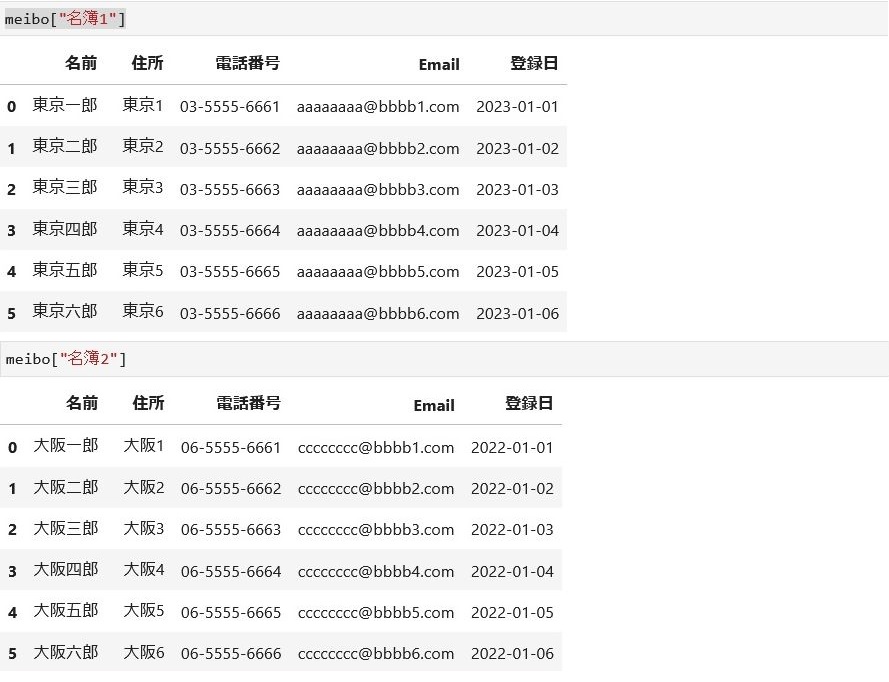
変数「meibo」に格納されたオブジェクトの型はディクショナリですので、キーは「名簿1」「名簿2」で値(オブジェクト)であるデータフレーム(DataFrame)はmeibo[‘名簿1’]、meibo[‘名簿2’]で取り出せます。
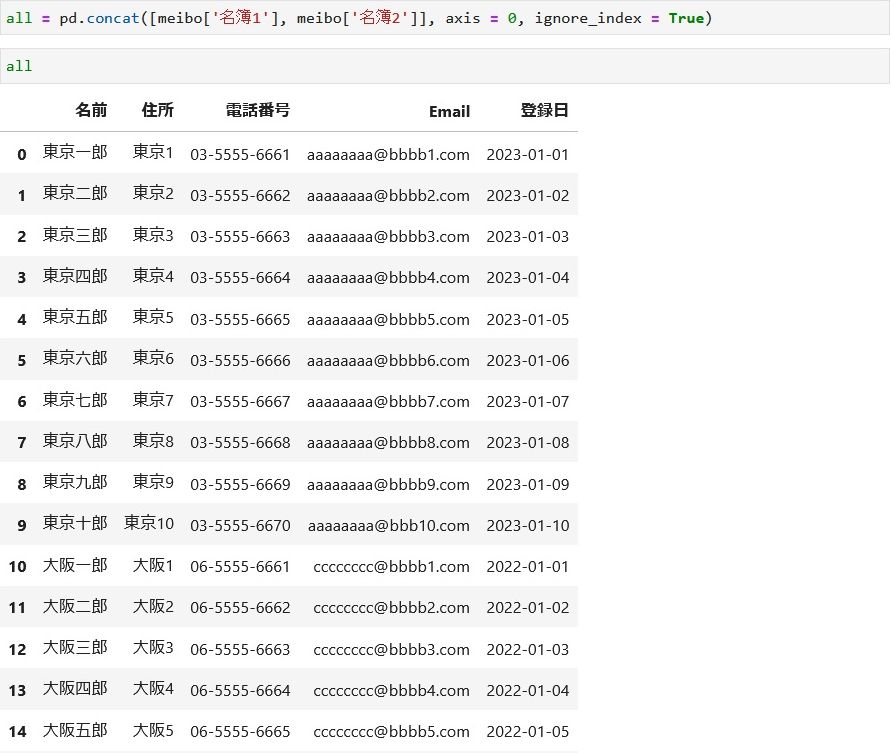
データフレームの結合
2つのデータフレーム(meibo[‘名簿1’]、meibo[‘名簿2’])を結合します。
データフレームのリストを渡し、連結軸を縦方向(axis = 0)にし、indexに意味がないので通番(ignore_index = True)にします。
all = pd.concat([meibo['名簿1'], meibo['名簿2']], axis = 0, ignore_index = True)
Excel にシート追加して書き込み
次のコードで、Excel にシート追加して書き込みます。
with pd.ExcelWriter('名簿.xlsx', engine = 'openpyxl', mode='a') as writer:
all.to_excel(writer, sheet_name='全名簿')
pandas.ExcelWriterのソース
DataFrame オブジェクトを Excel シートに書き込むためのクラス。
to_excel の中で使います。
class pandas.ExcelWriter(
path,
engine=None,
date_format=None,
datetime_format=None,
mode='w',
storage_options=None,
if_sheet_exists=None,
engine_kwargs=None,
**kwargs
)よく使う引数
path
str または typing.BinaryIO
xls または xlsx または ods ファイルへのパスを指定します。mode
{"w", "a"}、 デフォルト "w"
シートを追加するときは "a" を指定します。pandas.DataFrame.to_excel のソース
DataFrameを Excel シートに書き込みます。
単一のDataFrameを Excel .xlsx ファイルに書き込むには、ファイル名を指定するだけで済みます。
複数のシートに書き込むには、対象のファイル名でExcelWriterオブジェクトを作成し、ファイル内の書き込み先のシートを指定(mode)する必要があります。
一意のsheet_nameを指定することにより、複数のシートに書き込むことができます。
すべてのデータがファイルに書き込まれたら、変更を保存する必要があります。
https://github.com/pandas-dev/pandas/blob/v1.5.3/pandas/core/generic.py#L2202-L2382
def to_excel(
self,
excel_writer,
sheet_name: str = "Sheet1",
na_rep: str = "",
float_format: str | None = None,
columns: Sequence[Hashable] | None = None,
header: Sequence[Hashable] | bool_t = True,
index: bool_t = True,
index_label: IndexLabel = None,
startrow: int = 0,
startcol: int = 0,
engine: str | None = None,
merge_cells: bool_t = True,
encoding: lib.NoDefault = lib.no_default,
inf_rep: str = "inf",
verbose: lib.NoDefault = lib.no_default,
freeze_panes: tuple[int, int] | None = None,
storage_options: StorageOptions = None,
) -> None書き込みの実行
結合したデータフレーム「 all 」を読み込んだEXCELブック「名簿.xlsx」にシートを追加して書き込みます。追加するシート名は「全名簿」とします。
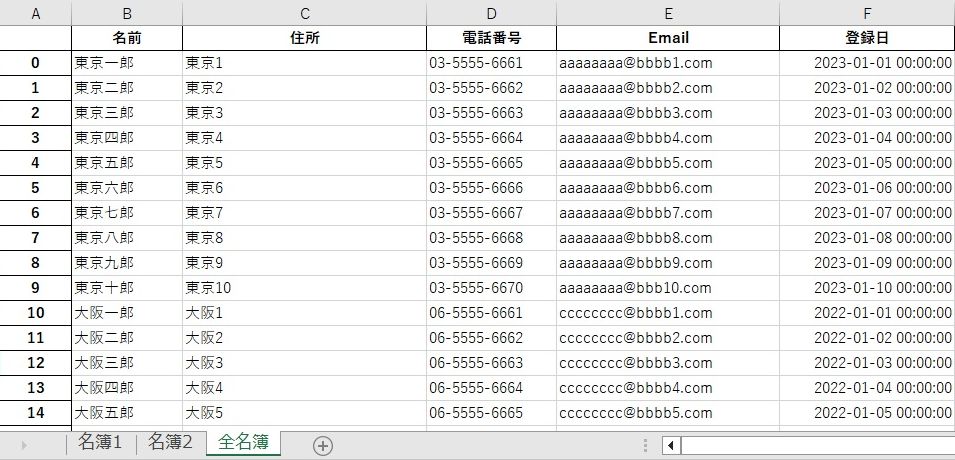
書き込みができましたが、登録日に時分秒の単位の値が付加されました。
with pd.ExcelWriter('名簿.xlsx', engine = 'openpyxl', datetime_format = 'YYYY-MM-DD', mode='a') as writer:
all.to_excel(writer, sheet_name='全名簿')としてみましたが変りませんでした。シートの標準書式なので、変えることができるので差支えはありません。
全コード
次のコードは全体を通したものです。Excel の VBA よりも簡単かもしれません。
import pandas as pd
meibo = pd.read_excel("名簿.xlsx", engine = "openpyxl", sheet_name = None)
all = pd.concat([meibo['名簿1'], meibo['名簿2']], axis = 0, ignore_index = True)
with pd.ExcelWriter('名簿.xlsx', engine = 'openpyxl', mode='a') as writer:
all.to_excel(writer, sheet_name='全名簿')